Assignments, Actual
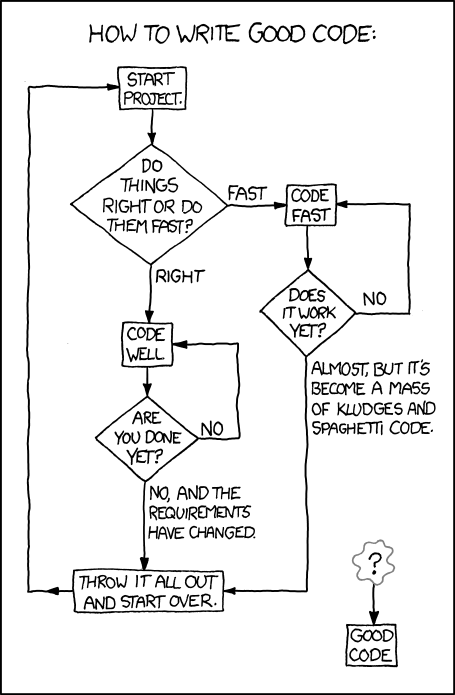
Milestone 5
For this week, your goal is to complete any missing bits in your implementation and write a distributed application that we call "7 degrees of Linus". The goal of that application is to compute all the people who worked on projects up to seven degrees of Linus Torvalds. Degree 1, is people who worked on the same projects as Linus, Degree 2 is people who worked on projects with Degree 1 folks. And so on.
This application will be discussed in a course video.
The deliverables are updated project document and code bases.
Milestone 4
For this week you should complete the distributed key value store implementation including the network layer. The goal will be to support a simple distributed word count application. The application was written by the company sales rep, as they were explaining eau2 to the client. It uses a number of imaginary APIs that you may not have. Feel free to ignore anything that clashes with your design. If this code is not helpful, you can reimplement something that works better for you. The code should be mostly correct, but since it is neither thoroughly documented, nor exhaustively tested, you should beware.
The input of the wordcount application is a single very large text file containing words separated by spaces. The output should be the list of different words and their counts. (The code provided only prints the number of different words)
This application will be presented in a course video.
class FileReader : public Writer { public: /** Reads next word and stores it in the row. Actually read the word. While reading the word, we may have to re-fill the buffer */ void visit(Row & r) override { ssert(i_ < end_); assert(! isspace(buf_[i_])); size_t wStart = i_; while (true) { if (i_ == end_) { if (feof(file_)) { ++i_; break; } i_ = wStart; wStart = 0; fillBuffer_(); } if (isspace(buf_[i_])) break; ++i_; } buf_[i_] = 0; String word(buf_ + wStart, i_ - wStart); r.set(0, word); ++i_; skipWhitespace_(); } /** Returns true when there are no more words to read. There is nothing more to read if we are at the end of the buffer and the file has all been read. */ bool done() override { return (i_ >= end_) && feof(file_); } /** Creates the reader and opens the file for reading. */ FileReader() { file_ = fopen(arg.file, "r"); if (file_ == nullptr) FATAL_ERROR("Cannot open file " << arg.file); buf_ = new char[BUFSIZE + 1]; // null terminator fillBuffer_(); skipWhitespace_(); } static const size_t BUFSIZE = 1024; /** Reads more data from the file. */ void fillBuffer_() { size_t start = 0; // compact unprocessed stream if (i_ != end_) { start = end_ - i_; memcpy(buf_, buf_ + i_, start); } // read more contents end_ = start + fread(buf_+start, sizeof(char), BUFSIZE - start, file_); i_ = start; } /** Skips spaces. Note that this may need to fill the buffer if the last character of the buffer is space itself. */ void skipWhitespace_() { while (true) { if (i_ == end_) { if (feof(file_)) return; fillBuffer_(); } // if the current character is not whitespace, we are done if (!isspace(buf_[i_])) return; // otherwise skip it ++i_; } } char * buf_; size_t end_ = 0; size_t i_ = 0; FILE * file_; }; /****************************************************************************/ class Adder : public Reader { public: SIMap& map_; // String to Num map; Num holds an int Adder(SIMap& map) : map_(map) {} bool visit(Row& r) override { String* word = r.get_string(0); assert(word != nullptr); Num* num = map_.contains(*word) ? map_.get(*word) : new Num(); assert(num != nullptr); num->v++; map_.set(*word, num); return false; } }; /***************************************************************************/ class Summer : public Writer { public: SIMap& map_; size_t i = 0; size_t j = 0; size_t seen = 0; Summer(SIMap& map) : map_(map) {} void next() { if (i == map_.capacity_ ) return; if ( j < map_.items_[i].keys_.size() ) { j++; ++seen; } else { ++i; j = 0; while( i < map_.capacity_ && map_.items_[i].keys_.size() == 0 ) i++; if (k()) ++seen; } } String* k() { if (i==map_.capacity_ || j == map_.items_[i].keys_.size()) return nullptr; return (String*) (map_.items_[i].keys_.get_(j)); } size_t v() { if (i == map_.capacity_ || j == map_.items_[i].keys_.size()) { assert(false); return 0; } return ((Num*)(map_.items_[i].vals_.get_(j)))->v; } void visit(Row& r) { if (!k()) next(); String & key = *k(); size_t value = v(); r.set(0, key); r.set(1, (int) value); next(); } bool done() {return seen == map_.size(); } }; /**************************************************************************** * Calculate a word count for given file: * 1) read the data (single node) * 2) produce word counts per homed chunks, in parallel * 3) combine the results **********************************************************author: pmaj ****/ class WordCount: public Application { public: static const size_t BUFSIZE = 1024; Key in; KeyBuff kbuf; SIMap all; WordCount(size_t idx, NetworkIfc & net): Application(idx, net), in("data"), kbuf(new Key("wc-map-",0)) { } /** The master nodes reads the input, then all of the nodes count. */ void run_() override { if (index == 0) { FileReader fr; delete DataFrame::fromVisitor(&in, &kv, "S", fr); } local_count(); reduce(); } /** Returns a key for given node. These keys are homed on master node * which then joins them one by one. */ Key* mk_key(size_t idx) { Key * k = kbuf.c(idx).get(); LOG("Created key " << k->c_str()); return k; } /** Compute word counts on the local node and build a data frame. */ void local_count() { DataFrame* words = (kv.waitAndGet(in)); p("Node ").p(index).pln(": starting local count..."); SIMap map; Adder add(map); words->local_map(add); delete words; Summer cnt(map); delete DataFrame::fromVisitor(mk_key(index), &kv, "SI", cnt); } /** Merge the data frames of all nodes */ void reduce() { if (index != 0) return; pln("Node 0: reducing counts..."); SIMap map; Key* own = mk_key(0); merge(kv.get(*own), map); for (size_t i = 1; i < arg.num_nodes; ++i) { // merge other nodes Key* ok = mk_key(i); merge(kv.waitAndGet(*ok), map); delete ok; } p("Different words: ").pln(map.size()); delete own; } void merge(DataFrame* df, SIMap& m) { Adder add(m); df->map(add); delete df; } }; // WordcountDemo
Deliverable: an updated report and a snapshot of the repository that runs this application.
Milestone 3
For this week your focus could be on distributing the key value store. That means eau2 should be able to run with multiple KV stores, and thus multiple instances of the application. While you can do this by plugging a network layer, you could also break down the work and "fake" the network and run multiple KV stores in the same process in different threads. The advantage of the pseudo-network approach is that debugging is a bit easier and you can focus on the design of the rest of the system without worrying about networking issues.
The goal for this week is to support the execution of the example shared in Milestone 1.
Deliverable: an updated report and a snapshot of the repository.
Milestone 2
For this week, we encourage you to focus on the key value store in the context of a single-node system (this means still no networking or concurrency required, if you are done early, you can start on those).
We envision two possible APIs to the store: the client interface which works on data frames only and (optinally) an internal, or private, interface that is used to store data hidden from the client.
A client program needs to be able to get, put, and wait_and_get on the KV store. Each of these operations take keys and (return) dataframes. Internally, you may want to store chunks of data frames or columns, etc. How you design this interface is up to you, as long as you support the client operations mentioned above.
A target for this week could be to get code similar to the following snippet to run on your system:
class Trivial : public Application { public: Trivial(size_t idx) : Application(idx) { } void run_() { size_t SZ = 1000*1000; double* vals = new double[SZ]; double sum = 0; for (size_t i = 0; i < SZ; ++i) sum += vals[i] = i; Key key("triv",0); DataFrame* df = DataFrame::fromArray(&key, &kv, SZ, vals); assert(df->get_double(0,1) == 1); DataFrame* df2 = kv.get(key); for (size_t i = 0; i < SZ; ++i) sum -= df2->get_double(0,i); assert(sum==0); delete df; delete df2; } };
Deliverable: A snapshot of your repository containing an updated version of your report and the current code base. All of the expectation from last week still hold. Grading on the report will look at the details of the description of the classes you have implemented. Grading for the code will be based on your ability to make the above example run, your tests and clean valgrind results. As previously bound the report writing time to 3 hours,
Milestone 1
Your goal is to design the architecture of the eau2 system from the requirements elicited by the company’s CEO when he sold the, yet-to-be-built, technology to their first customer. What follows is all that engineering has to go on, it has been made clear that losing this customer would likely result in an untimely end for the company.
Requirements call.
CEO: "We have a customer, it's Pear, if they pay we are set." |
|
CTO: "And... what... have... you... promised... them?" |
|
CEO: "Well, a distributed key/value store for big data analysis with a |
toolbox of machine learning algorithms running on GPUs demoed in two |
months." |
|
CTO: "Do you realize we have none of that implemented?" |
|
CEO: "Cut some corners, and get me a demo in a month." |
|
CTO: "What did you tell them, exactly?" |
|
CEO: "We did a walk through: One of their data analysts wants to find an |
anomaly in their pPhone manufacturing processes. She starts up eau2 on |
her desktop, and fires up a cluster in the background. Then, she |
loads a data set from a CSV file. Did you know that they have CSV |
files that over 100GB? Isn't that crazy? Anyway the data is loaded in |
memory, distributed over the cluster. The data analyst can issue |
interactive queries, such as 'find me all broken pPhones that were |
assembled by workers between 7 and 17 years old' and then cluster |
thoses according to the associated telemetry data'. Our system is |
insanely scalable and wicked fast. Each query comes back in a |
second. The analyst can keep refining queries until she finds what she |
is looking for then she can generate interactive visualization |
graphics." |
|
CTO: "Right... Right... So, no GPU. No machine learning. No visualization. |
Oh, and we don't deal with CSV, we use our in-house data format, |
schema-on-read." |
|
CEO: "Oh, wait but... that's not what I..." |
|
CTO: "And no interactive queries. We start batch. One master node with N |
compute nodes. We focus on tabular data, fewer than 100 columns and in |
the billions of rows. We read data once, ship it around the cluster so |
we can process queries in-memory." |
|
CEO: "Well... uh." |
|
CTO: "We assume that the data is read-only, to simplify consistency. We |
only support four data types. Write the code in CwC for readability by |
the script kiddies and escapes to C++ when/if needed. Can we get |
data?" |
|
CEO: "Uh, NDA..." |
|
CTO: "Example queries?" |
|
CEO: "You know, umh, they are going to be queries. Lots of queries. (pause) |
Machine learning! AI!" |
|
CTO: "Thanks, engineering will take it from here." |
First design meeting notes.
CTO: "Right, you have seen the transcript of the requirements, this is a |
mess. We are selling something we don't have and building something |
that we don't understand." |
|
Dev. Lead: "It's Tuesday." |
|
CTO: "Yeah." |
|
DvL: "So what corners can we cut to get this done in five weeks." |
|
CTO: "Design a system in three layers. At the bottom, there is a distributed |
KV store running on each node. Each KV store has part of the data, and |
the KV stores talk to exchange data when needed. All of the networking |
and concurrency control is hidden there. The level above provides |
abstractions like distributed arrays and data frames. These |
abstractions are implemented by calls to the KV store. Finally, the |
application layer is where users write code that sits on top of all |
this." |
|
DvL: "Let's talk KV store. What's a key and what's a value? What's the API?" |
|
CTO: "A key consists of a string and a home node. The key is used for |
searching, the home node tells which KV store own the data. We can |
assume a fixed set of nodes, each identified by an number between 0 |
and num_nodes. A value is a serialized blob. The KV store needs to |
support put(k,v), get(k) and getAndWait(k), where the latter is |
blocking." |
|
DvL: "Can K/V pairs be erased? Can values be overwritten?" |
|
CTO: "Only if you find that you need to and then, that is if you need to |
need to update values, use version numbers." |
|
DvL: "What's a distributed array?" |
|
CTO: "An array; its data is split in fixed-size chunks. Each chunk is stored |
as a KV pair. Different chunks can be on different nodes. So the Array |
itself is a list of keys and a cache." |
|
DvL: "What types do we need to support? For arrays." |
|
CTO: "Strings, for sure, some numerics, and booleans." |
|
DvL: "Do you care about speed?" |
|
CTO: "Not for now, we have to be able to read in, say 10GB, of data |
reasonably quickly, as we will tests at that scale, but don't focus on |
it. Bigger fish." |
|
DvL: "Paxos?" |
|
CTO: "God no. You know how that story ends. Start the nodes with a known |
lead node, get them to register, and then share the IPs. Also, no fault |
tolerance. Anything goes wrong, shutdown." |
|
DvL: "Can you share a bit of application code?" |
class Demo : public Application { public: Key main("main",0); Key verify("verif",0); Key check("ck",0); Demo(size_t idx): Application(idx) {} void run_() override { switch(this_node()) { case 0: producer(); break; case 1: counter(); break; case 2: summarizer(); } } void producer() { size_t SZ = 100*1000; double* vals = new double[SZ]; double sum = 0; for (size_t i = 0; i < SZ; ++i) sum += vals[i] = i; DataFrame::fromArray(&main, &kv, SZ, vals); DataFrame::fromScalar(&check, &kv, sum); } void counter() { DataFrame* v = kv.waitAndGet(main); size_t sum = 0; for (size_t i = 0; i < 100*1000; ++i) sum += v->get_double(0,i); p("The sum is ").pln(sum); DataFrame::fromScalar(&verify, &kv, sum); } void summarizer() { DataFrame* result = kv.waitAndGet(verify); DataFrame* expected = kv.waitAndGet(check); pln(expected->get_double(0,0)==result->get_double(0,0) ? "SUCCESS":"FAILURE"); } };
CTO: "We assume some Application class that has whatever functionality you |
need. This application will be started on each node of the system and |
the run_() method will be called on each instance. The this_node() |
method return the index of the current node. One node will run |
producer code to create a large dataframe with data and a small |
dataframe with the sum. The second node will get the dataframe and |
sum it too. The third will get both sums and output the result. |
Keys are created with a string and a home node index." |
|
DvL: "Can we change this API?" |
|
CTO: "A bit, but the examples we will get from customers will use it. So as |
long as you don't mind fussing with them to make them compile, feel |
free." |
|
DvL: "What's kv?" |
|
CTO: "It is a reference to the local KV store, probably a field of |
the Application class." |
|
DvL: "Can you update a dataframe?" |
|
CTO: "Let's say we can't. At least for now. For big data, my experience is |
that read-only is good enough for most apps." |
|
DvL: "What does fromArray do?" |
|
CTO: "It creates a dataframe, with SZ values taken from vals, and puts it in |
the kv store under key main. It returns the dataframe but in this |
example we don't need it. Any questions?" |
|
DvL: "Nope. Walk in the park. I'll start on the design document and get all |
of the reusable code to the new repo." |
You are to write a document describing the architecture of the system as you envision it. The section of that document are:
Introduction: where we give a high-level description of the eau2 system.
Architecture: where we describe the various part of eau2 at a high-level.
Implementation: where we describe how the system is built, this can include a description of the classes and their API, but only the class you deem relevant and worth describing. (For example: do not describe the utility classes.)
Use cases: examples of uses of the system. This could be in the form of code like the one above. It is okay to leave this section mostly empty if there is nothing to say. Maybe just an example of creating a dataframe would be enough.
Open questions: where you list things that you are not sure of and would like the answer to.
Status: where you describe what has been done and give an estimate of the work that remains.
Be precise and compact in your writing, avoid filler text. If you are not sure what should go in a section write less. You will update this document each week, so it will gradually be fleshed out. Best if you use markdown. Allocate no more than three hours to the writing. What you can do in that time is what you should deliver. If not perfect, it’ll improve next week.
The document is as much for you as it is for us. Grading will be based on superficial characteristics: spelling, grammar, adherence to the above description. Easy points. The following weeks will pay more attention to content.
Technical debt.
For the implementation you should focus on managing technical debt from your past efforts. You should create a new private GitHub repository for the project and move whichever code you want to retain from past work in that repository. This is a time to clean up your code and write tests. It is fine to simplify the code and only add what you are sure to need. You can always bring in more later.
You should reuse your array, dataframe, adapter classes. Feel free to strip them down to their essence – e.g. you can drop things like col/row names; these can be added later – anything you are not using in your examples or do not see a need for, drop. The smaller the code base the better.
Your project must have a Makefile with targets that:
build your code
run test case, there should be a test case that reads data, builds a dataframe, and does some trivial operation
run valgrind – if you are on a Mac this has to be done within docker.
Deliverable: a snapshot of your repository that contains a directory with your report and a directory with your code.
eau2/ |
Makefile |
report/ |
doc.md |
tests/ |
data/ // optional |
src/ |
Grading will be based on the presence of the above mentioned and code and test quality.
Assignment 6
Part 1. Networking, really
For this assignment you have to complete the design and implementation of a network communication layer for a distributed application, informed by your prototype from A5. The system consists of a rendezvous server (registrar) and an arbitrary number of nodes. A sketch of the architecture is provided below:
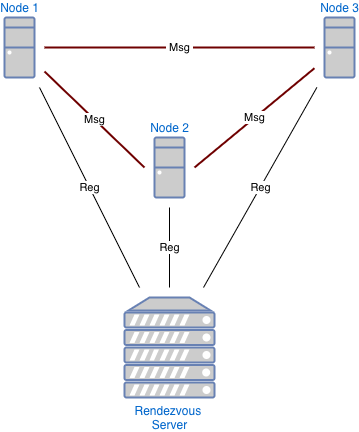
To participate in the system, a node needs to register with the rendezvous server, providing its IP address (and, optionally, a port) on which it will wait for connections from other nodes. The server will send a list of currently active nodes (a directory) to every active node. Once registered, a node can connect to any other node in the system directly to communicate via a predefined set of messages.
The communication layer for this system needs to support at least the following features:
- Startup, meaning:
Rendezvous server startup
Node startup and registration
Directory update from the server
Sending messages of arbitrary length and content between nodes
Teardown - orderly shutdown of the whole system
There are two levels to this task:
Design of a simple communication protocol. This includes the description of request and response types, as well as their sequencing.
Design and implementation of an API based on the communication protocol, using sockets for connection management.
The deliverables are: a memo documenting your design and implementation, and an implementation of the communication layer. Tests are for your confidence in your own work.
Submission structure:
part1/ |
MEMO.pdf |
src/ |
Makefile |
... .h files |
network.h # C/C++ |
server.cpp # rendezvous server driver in CwC |
client.cpp # node driver in CwC |
test/ |
... |
Your MEMO.pdf should be written with sufficient details for members of other teams to use your communication layer code. Add some use cases. Pay attention to details.
The API shouldn’t assume any particular IP addresses and ports used for the rendezvous server or the nodes, but you can assume that these will be provided via command line or a config file. Your example drivers can use hardcoded addresses (preferably in a way that’s easy to change) or accept them as command line options.
The API should be complete in the sense that it abstracts and hides the details of establishing a connection, as well as sending, receiving, and validation of requests and responses.
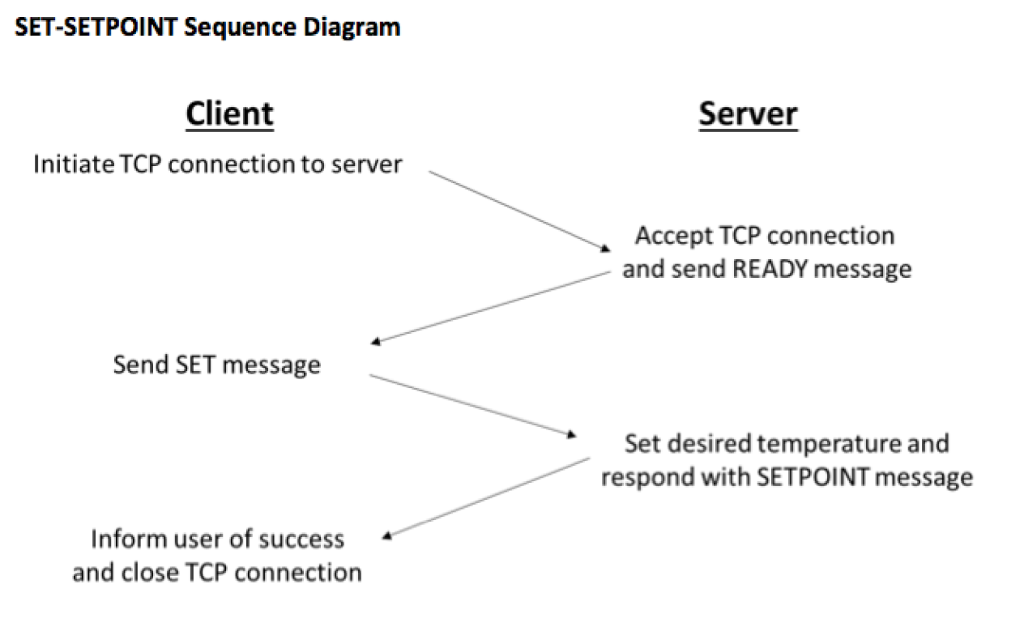
Hints: For documenting the sequencing of communication, you might find sequence diagrams to be useful: example and another example.
{kind=link}
{kind=link}
Part 2. Serially, really
Your task is to implement a serialization support class and demonstrate how to use it to serialize elements of a DataFrame. The term serialization refers to the transformation of a set of objects in memory into a sequence of bytes (chars) that can be sent through the network or stored on disk. This includes deserialization, that is, the transformation of a sequence of bytes back into an object of the correct type. Your design will likely be used in the near future. The deliverable is a MEMO.pdf describing your design, along with use cases. Code is supporting evidence, in the form of a prototype exemplifying serialization and deserialization. You should be able to serialize at least the following classes (the names can be changed to match your code base):
class StringArray { |
String* vals_; |
... |
}; |
|
class DoubleArray { |
dobule* vals_; |
... |
}; |
|
enum class MsgKind { Ack, Nack, Put, |
Reply, Get, WaitAndGet, Status, |
Kill, Register, Directory }; |
|
class Message : public Object { |
MsgKind kind_; // the message kind |
size_t sender_; // the index of the sender node |
size_t target_; // the index of the receiver node |
size_t id_; // an id t unique within the node |
... |
}; |
|
class Ack : public Message { |
}; |
|
class Status : public Message { |
String* msg_; // owned |
... |
}; |
|
class Register : public Message { |
sockaddr_in client; |
size_t port; |
}; |
|
class Directory : public Message { |
size_t client; |
size_t * ports; // owned |
String ** addresses; // owned; strings owned |
... |
}; |
Submission structure:
part2/ |
MEMO.pdf # Protocol description |
src/ |
... .h files |
serial.h |
main.cpp # driver file in CwC |
test/ |
... |
You MEMO.pdf should be written with sufficient details for members of other teams to use your serialization API. Pay attention to details.
Assignment 5
Part 1. Concurrency, really
Your goal for Part I is to improve your implementation of pmap() and write a MEMO.pdf describing your experimental evaluation. For this part, we will grade you largely on the report (40 out of 50 points); your code serves as supporting evidence. Your report should be single spaced, well formatted, carefully worded. Approximately 5 pages should suffice. In particular, your evaluation should demonstrate that for two tasks of your choosing, pmap performs as well or better than map, in terms of end-to-end performance. To that end, you will do the following:
Find or create datafile.txt. You need to have some data to work on. These data can come from some real world site or can be synthetic. To give reliable results the data should be "large enough": a data file of 100 MB in size with at least 10 columns.
Pick tasks. You need to define two Rower subclasses that can be given to pmap(). The second Rower subclass (this is to say, the "function" this subclass describes) should be a far bit more expensive than the first one.
Design an experiment to measure the performance increase of pmap over map—
using the performance on map as a baseline— on executing these two Rower subclasses. Your experiment should vary the size of the input you use, gradually increasing the number of rows from the data file that you consume. The source code you execute for your experiment should be in {bench.cpp}. You may find it useful for your Makefile to do the timing measurements. Run your experiment on two computers with different characteristics. Ideally, one of these would be a laptop and the other a desktop. But if your pair does not have access to a desktop, two differently configured laptops will do.
Write MEMO.pdf, a report describing the preceding and the results.
Your report should contain the following sections:
Introduction - describes the goal of the report (a description of an experimental evaluation).
Implementation - a section describing your implementation of pmap().
Description of the analysis performed - a section describing your data—
why and how you created them, what you are going to measure and how (e.g. repeated numbers of runs, number and size of iterations), and describe also the HW/SW infrastructure you use in your experiment. Comparison of experimental results Provide and explain your results in both text and graphical form. Describe the sources of non-determinism.
Threats to validity What could make your results wrong for someone else?
Conclusions A section summarizing the work.
Your datafile.txt will be too large to submit via handins. Instead, you should host this file somewhere (e.g. github.com). Your Makefile should pull down this file down as a part of executing it. HINT: This 100MB file will be too large to check into many VCSs. Compress (e.g. zip or tarball) datafile.txt first, and commit that.
Deliverables: |
part1/ |
MEMO.pdf # Your report |
... # Any and all necessary .h files |
bench.cpp # Benchmark file |
Makefile # With targets |
build # builds the executable |
run # downloads datafile and executes your code against it. |
Part 2. Networking, prototyped
Eventually, for the project, you will need to have a working network layer. In Part 2 you will prototype a networking layer for inclusion in the upcoming project. "Prototyping" means creating something that works well enough to demo, but likely not a finished product. More importantly, writing up a report describing what you have implemented. This is an open-ended assignment. You will not be graded on how much functionality you implement but rather on the quality of the report describing this implementation.
In term of functionality, you should at least support registration and simple directed communication. For registration, we assume one single server with a known address is contacted by a fixed number of clients. The clients share their address with the server, which then sends all addresses to its clients. Directed communication means that each client can send messages directly to any other client. Your network layer can be written using the POSIX networking library functions, but should be encapsulated in its own class. Server and client need to take IP address as arguments on the command line:
$ ./server -ip 102.168.0.1 |
Deliverables: |
part2/ |
MEMO.pdf ## PDF |
src/ |
... other .h files |
network.h # CwC |
client.cpp # CwC |
server.cpp # CwC |
Makefile |
build # compile |
run # run |
test/ |
... your tests |
The MEMO.pdf should be a PDF file, single-spaced, no more than two pages long. It should have an Introduction, describing what you have implemented in high-level terms, a Design section, explaning you design and showing your API and a Challenges and Open issues section, telling the readers about problems you faced, and issues that remain to be solved. Write clearly. Assume this is read by your coop boss.
Erata: The deliverables for Part 2 originally listed a single .cpp file, main.cpp. This has been updated with separate source files for the client and server code.
Assignment 4
Part 1. Implementation
You just submitted an API for the dataframe class. However, management chose the instructors’ API. You shall find our API at the bottom of this assignment. Your task is to implement our API in CwC and write tests for your implementation. This is code that you are likely to reuse later.
You are free to add additional classes and methods (of course, you should document them in your README.md, explaining what they are and why you wanted them.)
If you see a mistake in our API, report it in a public Piazza post and suggest the fix for it. The moral-equivalent of PRs are preferred over the moral-equivalent of issues. Each "separate" bug report should be in a separate Piazza post (if a single change in functionality requires edits to multiple lines of code, requesting all of those edits should be in the same post). The class will synchronize on the implementation of this one API, so we will accept few changes, and if we accept one, it will be universal across the course and mandatory. Consequently, we will only entertain bug reports "early on." Absent this, you shall follow our API to the letter.
The following program we provide you in basic_example.cpp should compile and run without change (meaning that dataframe.h must include everything this program needs):
#include "dataframe.h" int main() { Schema s("II"); DataFrame df(s); Row r(df.get_schema()); for(int i = 0; i < 100*1000*1000; i++) { r.set(0, i); r.set(1, i+1); df.add_row(r); } assert(df.get_int(0,1) == 1); return 0; };
For this assignment, be very careful to use exactly the names as given down to the capitalization and spelling; we will automate the testing of your assignments. Use the helper.h, object.h and string.h classes we provide you. Do not change any of those three files; in the course of testing your submission we will copy our original versions into the top-level of your submission. For similar reasons, your submission should also include exactly the Dockerfile that we give you. Some previous projects had trouble scaling, in particular due to doubling of array sizes when they need to grow. In your implementation, make sure that you have arrays with O(1) element access time, but also which never copy the payload.
The basic_example.cpp we provide you is for some basic sanity checking of your implementation against ours. We do not have an exhaustive test suite. Luckily, you will help us with that. For this assignment you shall use Google Tests for your own private test suites, and you should be thorough. However, in addition to that usual, regular, rigorous testing that you perforce implement, your submission shall include 7 extra Google Test files, with a single test in each file. Each of the 7 tests you write and submit will exercise some part(s) of your implementation of our API. These 7 tests you submit to us should not test or measure the behavior of functionality unspecified by the API. Thoroughly comment these tests! Remember, tests are code too.
It is our intention to take these 7 test files from your submission, and run these tests against every pair’s submitted implementation. We will merge the tests we have written together with the tests from every pair’s submission; this will form our automated test suite. We take our implementation of the API as canonical; we consider tests that do not succeed against our implementation to be "incorrect", and we will throw them out. Of those 7 tests you submit, you can earn an extra point for each submission that you break (excluding your own) with a valid test. (Up to a maximum of 20 points).
Erata: The print method on dataframes was missing. The IntColumn had a field. The default constructor for StringColumn was missing. The specification of the visit method was missing a description of the first argument. Access to out of bound indicies was set to undefined. Duplicate column and row names was set to undefined. The second constuctor of DataFrame was modified to say that columns are created empty. The Row set method’s comment was change to state the strings are external. Some typos.
Your README.md should give:
an introduction to your implementation,
an overview of the design choices that you made,
use cases (the "examples" step from the design recipe) of things one can do with your data frame.
You shall submit Part I in a directory named part1; we detail below the structure of the entire submission.
Part 2. Concurrency
You will submit Part II in a directory named part2.
Copy your completed dataframe.h, to a new file modified_dataframe.h, and in modified_dataframe.h add the following method to your dataframe class:
/** This method clones the Rower and executes the map in parallel. Join is * used at the end to merge the results. */ void pmap(Rower& r)
Then, in a parallel_map_examples.cpp file, write 2-3 examples which clearly demonstrate that on a multi-core machine your implementation of pmap is asymptotically faster than your implementation of plain map.
The PARALLELMAPREADME.md in your submission for Part II shall:
have example use-cases of your pmap,
describe your design for your parallel map,
describe how the examples in your parallel_map_examples.cpp file demonstrate that pmap is faster, and
describe issues that you encountered in implementing your parallel map.
You are free to add additional classes and methods (of course, you should document them in your PARALLELMAPREADME.md, explaining what they are and why you wanted them.)
Your submission.zip should have the following directory structure:
submission.zip/ |
Dockerfile |
Makefile // with the following targets: |
first // go to the part1 directory, and build & run tests in docker |
second // go to the part2 directory, and build & run parallel map tests in docker |
object.h // as provided, unchanged |
string.h // as provided, unchanged |
helper.h // as provided, unchanged |
... // all other .h files required to compile and run your tests. |
part1/ |
README.md |
CMakeLists.txt |
CMakeLists.txt.in |
dataframe.h |
basic_example.cpp |
submitted_test_1.cpp |
submitted_test_2.cpp |
submitted_test_3.cpp |
submitted_test_4.cpp |
submitted_test_5.cpp |
submitted_test_6.cpp |
submitted_test_7.cpp |
personal_test_suite.cpp |
... // other test files, if you separate your test suites |
part2/ |
PARALLELMAPREADME.md |
CMakeLists.txt |
CMakeLists.txt.in |
modified_dataframe.h |
parallel_map_examples.cpp |
parallel_map_personal_test_suite.cpp |
... // other test files, if you separate your test suites |
We will initially test your assignment by running unzip submission.zip; make. We will of course do more to run your submitted tests against others’ assignments.
Below is our API that you should implement. Note that our API does not deal with missing values. That’s for future work.
/************************************************************************** * Column :: * Represents one column of a data frame which holds values of a single type. * This abstract class defines methods overriden in subclasses. There is * one subclass per element type. Columns are mutable, equality is pointer * equality. */ class Column : public Object { public: /** Type converters: Return same column under its actual type, or * nullptr if of the wrong type. */ virtual IntColumn* as_int() virtual BoolColumn* as_bool() virtual FloatColumn* as_float() virtual StringColumn* as_string() /** Type appropriate push_back methods. Calling the wrong method is * undefined behavior. **/ virtual void push_back(int val) virtual void push_back(bool val) virtual void push_back(float val) virtual void push_back(String* val) /** Returns the number of elements in the column. */ virtual size_t size() /** Return the type of this column as a char: 'S', 'B', 'I' and 'F'. */ char get_type() }; /************************************************************************* * IntColumn:: * Holds int values. */ class IntColumn : public Column { public: IntColumn() IntColumn(int n, ...) int get(size_t idx) IntColumn* as_int() /** Set value at idx. An out of bound idx is undefined. */ void set(size_t idx, int val) size_t size() }; // Other primitive column classes similar... /************************************************************************* * StringColumn:: * Holds string pointers. The strings are external. Nullptr is a valid * value. */ class StringColumn : public Column { public: StringColumn() StringColumn(int n, ...) StringColumn* as_string() /** Returns the string at idx; undefined on invalid idx.*/ String* get(size_t idx) /** Out of bound idx is undefined. */ void set(size_t idx, String* val) size_t size() }; /************************************************************************* * Schema:: * A schema is a description of the contents of a data frame, the schema * knows the number of columns and number of rows, the type of each column, * optionally columns and rows can be named by strings. * The valid types are represented by the chars 'S', 'B', 'I' and 'F'. */ class Schema : public Object { public: /** Copying constructor */ Schema(Schema& from) /** Create an empty schema **/ Schema() /** Create a schema from a string of types. A string that contains * characters other than those identifying the four type results in * undefined behavior. The argument is external, a nullptr argument is * undefined. **/ Schema(const char* types) /** Add a column of the given type and name (can be nullptr), name * is external. Names are expectd to be unique, duplicates result * in undefined behavior. */ void add_column(char typ, String* name) /** Add a row with a name (possibly nullptr), name is external. Names are * expectd to be unique, duplicates result in undefined behavior. */ void add_row(String* name) /** Return name of row at idx; nullptr indicates no name. An idx >= width * is undefined. */ String* row_name(size_t idx) /** Return name of column at idx; nullptr indicates no name given. * An idx >= width is undefined.*/ String* col_name(size_t idx) /** Return type of column at idx. An idx >= width is undefined. */ char col_type(size_t idx) /** Given a column name return its index, or -1. */ int col_idx(const char* name) /** Given a row name return its index, or -1. */ int row_idx(const char* name) /** The number of columns */ size_t width() /** The number of rows */ size_t length() }; /***************************************************************************** * Fielder:: * A field vistor invoked by Row. */ class Fielder : public Object { public: /** Called before visiting a row, the argument is the row offset in the dataframe. */ virtual void start(size_t r) /** Called for fields of the argument's type with the value of the field. */ virtual void accept(bool b) virtual void accept(float f) virtual void accept(int i) virtual void accept(String* s) /** Called when all fields have been seen. */ virtual void done() }; /************************************************************************* * Row:: * * This class represents a single row of data constructed according to a * dataframe's schema. The purpose of this class is to make it easier to add * read/write complete rows. Internally a dataframe hold data in columns. * Rows have pointer equality. */ class Row : public Object { public: /** Build a row following a schema. */ Row(Schema& scm) /** Setters: set the given column with the given value. Setting a column with * a value of the wrong type is undefined. */ void set(size_t col, int val) void set(size_t col, float val) void set(size_t col, bool val) /** The string is external. */ void set(size_t col, String* val) /** Set/get the index of this row (ie. its position in the dataframe. This is * only used for informational purposes, unused otherwise */ void set_idx(size_t idx) size_t get_idx() /** Getters: get the value at the given column. If the column is not * of the requested type, the result is undefined. */ int get_int(size_t col) bool get_bool(size_t col) float get_float(size_t col) String* get_string(size_t col) /** Number of fields in the row. */ size_t width() /** Type of the field at the given position. An idx >= width is undefined. */ char col_type(size_t idx) /** Given a Fielder, visit every field of this row. The first argument is * index of the row in the dataframe. * Calling this method before the row's fields have been set is undefined. */ void visit(size_t idx, Fielder& f) }; /******************************************************************************* * Rower:: * An interface for iterating through each row of a data frame. The intent * is that this class should subclassed and the accept() method be given * a meaningful implementation. Rowers can be cloned for parallel execution. */ class Rower : public Object { public: /** This method is called once per row. The row object is on loan and should not be retained as it is likely going to be reused in the next call. The return value is used in filters to indicate that a row should be kept. */ virtual bool accept(Row& r) /** Once traversal of the data frame is complete the rowers that were split off will be joined. There will be one join per split. The original object will be the last to be called join on. The join method is reponsible for cleaning up memory. */ void join_delete(Rower* other) }; /**************************************************************************** * DataFrame:: * * A DataFrame is table composed of columns of equal length. Each column * holds values of the same type (I, S, B, F). A dataframe has a schema that * describes it. */ class DataFrame : public Object { public: /** Create a data frame with the same columns as the given df but with no rows or rownmaes */ DataFrame(DataFrame& df) /** Create a data frame from a schema and columns. All columns are created * empty. */ DataFrame(Schema& schema) /** Returns the dataframe's schema. Modifying the schema after a dataframe * has been created in undefined. */ Schema& get_schema() /** Adds a column this dataframe, updates the schema, the new column * is external, and appears as the last column of the dataframe, the * name is optional and external. A nullptr colum is undefined. */ void add_column(Column* col, String* name) /** Return the value at the given column and row. Accessing rows or * columns out of bounds, or request the wrong type is undefined.*/ int get_int(size_t col, size_t row) bool get_bool(size_t col, size_t row) float get_float(size_t col, size_t row) String* get_string(size_t col, size_t row) /** Return the offset of the given column name or -1 if no such col. */ int get_col(String& col) /** Return the offset of the given row name or -1 if no such row. */ int get_row(String& col) /** Set the value at the given column and row to the given value. * If the column is not of the right type or the indices are out of * bound, the result is undefined. */ void set(size_t col, size_t row, int val) void set(size_t col, size_t row, bool val) void set(size_t col, size_t row, float val) void set(size_t col, size_t row, String* val) /** Set the fields of the given row object with values from the columns at * the given offset. If the row is not form the same schema as the * dataframe, results are undefined. */ void fill_row(size_t idx, Row& row) /** Add a row at the end of this dataframe. The row is expected to have * the right schema and be filled with values, otherwise undedined. */ void add_row(Row& row) /** The number of rows in the dataframe. */ size_t nrows() /** The number of columns in the dataframe.*/ size_t ncols() /** Visit rows in order */ void map(Rower& r) /** Create a new dataframe, constructed from rows for which the given Rower * returned true from its accept method. */ DataFrame* filter(Rower& r) /** Print the dataframe in SoR format to standard output. */ void print() };
Assignment 3
Part I: Performance Issues
Part I of this week’s assignment is to evaluate and compare the performance
and design of several data adapters. This is yet another important task that
comes up in real-world software development roles: e.g. choosing a platform,
library, application stack, or 3rd party software vendor. Management has put
out an RFP for
a data adapter to use on an upcoming project. They have received 21
submissions. All the submitted products are roughly equivalent in cost; no
need to worry about that. In any case this project is so critical—

This is where you come in. As we discussed in class this week, accurately
measuring and comparing the performance of different pieces of software is a
non-trivial task. What does "performance" mean for a data adapter? How
should we compare software written in compiled languages to that written in
interpreted languages? Are two pieces of software equally "capable", or is
one less fully-featured than the other—
Like we said at the outset, your mission in Part I is to measure and compare the performance of the submissions and assess the quality of their designs. Pick six of them from this set (you can include more than six in your analysis, but don’t have to) and summarize your findings in a memo to management that describes how you performed your analysis, the comparison of the relative performance of the submitted products (whatever that happens to mean), and finally a recommendation to management of which product to select.
To do this you will have to design a set of benchmarks, carry out measurements, document the goals, scope and outcomes of your experiments. You will also have to look at the code of the different artifacts.
Deliverables: Your deliverable for Part I is a file named MEMO.pdf, in a directory part1. This memo should have at least the following sections, clearly labelled. The section names are bolded, and each is followed by a description of its contents.
Introduction - describes the goal of the report (an ends-based study of performance and of code quality) that will allow us to select a data adapter for our project.
Description of the analysis performed - describe your benchmarks, why and how you created them. Describe what you are going to measure and how. (e.g. builds vs. runs vs. iterations) Describe also the HW/SW infrastructure (OS, docker?, compiler, ...)
Comparison of the products’ relative performance Include graphs and an ordered list (best first). Avoid single runs. Describe the sources of non-determinism.
Threats to validity What could make your results wrong for someone else?
Recommendation to management which consists of a list of the projects in order of preference, and a rationale for your top choice (consider also code quality and effort to integrate).
Hints: Read the material shared on Piazza about performance. Think about what a reasonable workload would be for a data adapter (i.e. guess what kind of files will it have to process?) and design benchmarks that will measure performance. Avoid single measurements, avoid single runs, make sure to document the configuration. A good way to represent numeric information is through charts or graphs. The evaluation of a memo will take into account its format, its information content, and basic English writing (typos, grammar mistakes). The latter will affect your grade in a serious manner if the mistake allows a misinterpretation of a sentence or if the mistake makes an interpretation extremely difficult.
Part II: Design
Part of the upcoming project will be to design the API of a so-called DataFrame. This will be a data structure capable of holding values of the four SoR types from your previous work. The intended use for data frame is to store large amounts of data in a memory efficient manner. Make sure to make the API general enough so it is possible, at a later time, to add implementation of, for example, compressed columns, or implementations that may offload data to disk.
In terms of API design, all the information you have been given is the following design notes from an app architect who was inspired by the data frames used in the R language (Python also has a similar concept, copied from R) and tried to transcribe them into someting that looks like CwC. Your job is to think through a reasonable design that allows to do at least what you see in the notes, but add the features that you would think would make sense. You may have to look up examples of data frame usage on the internet. If your design departs from these notes, that’s not a problem as the notes are more akin to skteches, that fine, just make sure to document the reason for the departures so the architect is aware.
Architect’s Notes:
A data frame is used for storing data tables. It is an ordered sequence of (optionally named) columns of equal length. For example, the following variable df is a data frame containing three columns n, s, b.
n = new IntColumn(2, 3, 5); |
s = new StringColumn("aa", "bb", "cc"); |
b = new BoolColumn(1,0,1); |
df = new DataFrame(n, s, b); # df is a data frame |
DataFrames know how to print themselves:
mtcars.print(); |
mpg cyl disp hp drat wt ... |
Mazda RX4 21.0 6 160 110 3.90 2.62 ... |
Mazda RX4 Wag 21.0 6 160 110 3.90 2.88 ... |
Datsun 710 22.8 4 108 93 3.85 2.32 ... |
............ |
The top line of the table, called the header, contains the column names. If columns do not have names, numbers will be displayed. Each horizontal line afterward denotes a data row, which begins with the name of the row (if any), and then followed by the actual data. Each data member of a row is called a cell.
To retrieve data in a cell, we would enter its row and column coordinates. The coordinates begins with row position, then followed by a comma, and ends with the column position. The order is important.
Here is the cell value from the first row, second column of mtcars.
mtcars.get(1, 2); |
6 |
Moreover, we can use the row and column names instead of the numeric coordinates.
mtcars.get("Mazda RX4", "cyl"); |
6 |
The number of data rows in the data frame is given by the nrow function.
mtcars.nrow(); # number of data rows |
32 |
And the number of columns of a data frame is given by the ncol function.
For more operations that would be cool to have, go to this paper: https://arxiv.org/pdf/1908.06719.pdf it’s written by database folks but they are not 100% wrong.
Deliverables: a directory named part2 which contains .h files for all the classes you need and a README.md file with a high-level description of your API, give use-cases (e.g. code snippets with explanation) to illustrate how the API could be used.
Hint: We expect you to read about the concept of data frames on your own. From what you have read and what we have written above, you are to think of use cases that feel reasonable. Following those use cases, you must design a handful of classes, and those classes’ methods, that could be implemented in CwC. Motivate your design, many designs are possible but they should be motivated and backed up by some rational argument.
Assignment 2
Software development often involves multiple teams that must cooperate on a tight schedule. In A2, you will play two simultaneous roles. Part 1 has you act as a dev pair working on key data structures that will be used in your project. For Part 2, your role is to support multiple dev pairs and be responsive under pressure.
Part 1. Implementation
Your pair is implementing data structures for an upcoming project. The project design is still in flux, from water cooler conversations, you heard something about scalable, high-performance, distributed computing. The dev lead has picked a subset of C++ called CwC, not your preferred choice, but the project is too good to pass over language choice.
What you know is that the data structures should be "insanely fast" and "totally scalable" – though those terms were never defined. What you know for sure is that you will need some variants of Array, Queue and Map. Since CwC does not have templates or generics, you will have to think hard how to avoid massive amounts of code duplication. Luckily, your colleagues, the Spec pair, have designed an API (and even test cases!) for the proposed data structures. Your implementation must match their design as other parts of the system will expect the method and classes to behave as specified.
In terms of what needs to be delivered, there should be Array classes which supports int, float, bool and String. Arrays should grow when values are pushed back, and whatever else it takes to support reads and writes. The Queue class should support normal push and pop operations, the values that need to be supported are Strings and Objects. It is likely that the application will push and pop extremely frequently; the Queue should only use new and delete occasionally as these can be a bottleneck for speed. Lastly, your Map should support mapping Strings to Strings and generally Object to Object. The performance of the Map class should be tuned to avoid pathological cases by rehashing when the load gets too high. Aim for fast code, whatever that means.
Via the git repository whose name you submitted with your last assignment, we will provide you the clone URLs of 3 Github repositories, each containing the specification of one data structure, and the tests needed to run it.
You must pass these repositories’ test suites! Briefly, if you think the tests or spec are broken or mistaken, file issues or pull requests with the designers (one issue/pull request per flaw, as is the standard practice.) There may also be missing tests, for example, for some of the classes you implemented that were not part of the original spec. You have to make sure that the proper tests are added to the test file. Untested code is not something your company will ever use. Watch their repository for updates, and stay on the issues, so that when their test suites are corrected you get the latest version.
The deliverables for Part I should be stored in a new directory named part1 containing:
.h files with your data structures named array.h, queue.h and map.h,
a Makefile, contents described below
a memo titled MEMO.md, also described below, and
object.h and string.h (and anything else you need to compile and run).
For each of the 3 repos that you were given, it should be possible to check out their tests, compile them with your .h files, and make their tests pass without errors. To demonstrate this, your Makefile should have targets so that:
make testArray,
make testQueue‘, and
make testMap
compile and run each of those test files. (These make targets, and your submission, should use the most recent, updated test files and conform to the updated spec that you receive from the designers.) Optionally, you may also provide a .cpp file with additional tests.
Your MEMO.md should be a note to management that does the following:
Briefly explain how your implementation allows supporting the needs of the project as described above. This part should be short but convince the reader that your implementation fulfills all the stated requirements.
Briefly critique the designs and tests you were given. This part should have three sections; one for each of the three repos you are given. Each of those three repo sections should have the following subsections:
Documentation quality: comment on the quality of the specification, point out any deficiencies or issues you encountered.
Responsiveness: share, with management, your experience working with that Spec pair. When you had issues, did they respond? How did you communicate?
Test quality: address the issue of how good the tests were. Did you feel you needed to write your own tests? If so why?
Part 2. Design Maintenance
The specification you wrote in A1 Part II has been given to other pairs for implementation. In fact they may have been given to multiple implementers. Your job is to update your specification and tests in response to requests from those pairs. You may have to negotiate when faced with conflicting demands. You have to be responsive as the dev pairs depend on your specification.
The deliverable for this part is the updated GitHub repository from a1 containing your tests and spec. When you submit your assignment, include this updated part2 directory.
Deliverables
For a2, you should submit on handins a single zip archive, containing the directories named part1 and part2.
More details and clarifications will be issued during the week. Watch Piazza.
Hint: Grading will consist of us checking out tests from the spec repositories and running them. If they do not compile, no points can be awarded. We are aware that the tests are written by another team – it is your job to make sure that they compile with your code. It is also your job to convince the other team to write good and exhaustive tests. We will also take into account any issues that you report in your memo. The final grade may be influenced by your performance in both part 1 and part 2.
Assignment 1
Your first SwDv pair programming assignment consists of two components: implementation and design. The implementation component can be done in any language as long as we can run it in docker.
Part I: Implementation
You are working in a large company that must process data feeds from many sources; your task is to write a data adapter for a new data format. The data adapter reads files in that format and builds dataframes that can be processed by existing parts of your infrastructure. For now you only need to write the adapter.
Speed and memory efficiency are important as data volumes are large. Some of the files that you will have to read are too large to fit in RAM, so your data adapter will have to be careful about its memory use and be able to read parts of a file.
The data format you are processing is called SoR, an acronym for schema-on-read, i.e., when the type and structure of a data file is only discovered as you read it.
A SoR file is a sequence of rows. Each row is a sequence of fields. A field can be either missing a value, or contain a value of one of four SoR types: BOOL, INTEGER, FLOAT, or STRING. The range of values that can be stored in a field is specified as follows: a BOOL can be either 0 (false) or 1 (true), an INTEGER can be any C++ int value, a FLOAT can be any C++ float number, and a STRING is a sequence of C++ characters (a string can’t be longer than 255).
SoR files are stored as plain text, fields start with "<" and end with ">", rows are delimited by "\n", the end of line character. A missing value is an empty field (i.e. "<>" or the absence of a field for any number of trailing fields in a row). Integers are written as a sequence of digits with an optional leading sign. Floating point numbers are like integers but with the option of having a decimal point amongst the digits. Booleans are either "1" or "0". Strings can be written either as a sequences of characters without spaces or as a double quote delimited sequence of characters with spaces. Line breaks are not allowed in strings.
The following is an example of a row with four fields:
< 1 > < hi > < +2.2 >< " bye "> |
Spaces around delimiters are ignored. So the above means:
<1><hi><+2.2><" bye "> |
For simplicity, we say that the following are invalid fields:
<1. 2> // space after dot |
<bye world> // string with spaces and without quotes |
<+ 1> // space after the + |
It is valid for two rows in the same file to have different numbers of fields.
The behavior of your code for rows with invalid fields is unspecified. Generally SoR files are generated so you can expect they are well formed. When you write your tests, focus on correct SoR files and valid queries.
When you read a file (or part of a file), you should first infer the file’s schema, and then construct the columnar representation. To infer the schema, scan the first 500 lines (or the whole file if it is smaller), find the row with most fields. This gives you the number of columns. Then, for each column look at the values for that column in the rows you read: ignoring missing values, if any values is a STRING, then the whole column is of STRING type. Otherwise, if any of the values is a FLOAT, then the column is of FLOAT type. Otherwise, if you find a value with a sign or a value larger than 1, then the column is INT. Otherwise the column is BOOL. Once you have inferred the schema for the file, create columns of these types and populate them with values found in the corresponding fields of the rows you have been asked to read.
If you find a row that does not match the schema, either ignore that row or replace fields that do not match with missing.
When read a part of a file (i.e. when -from is not 0 and -len is not the number of bytes in the file), discard the first and last row as they may be partial. This means, starting at -from, ignore all characters until the first line break. And discard all characters after the last line break before you get to from + len.
To interface with the rest of your company’s systems, you program should turn the data it read into a columnar format. What this means is, rather than having data arranged in rows, you should create columns, each column should have a type and hold values of that type or missing.
You are free to make design decisions that will improve memory usage and speed, as long as they preserve the columnar representation described above. In future assignments, we will measure the performance of your code. For the final project, you will have to use someone else’s data adapter – so your code may end up being used by other people!
Since your program can be in any language, we expect that you will provide us with an executable (or script), named sorer, and a docker file in which we can build it and call it. We will test your code by passing command line arguments and observing results printed on stdout. Note that uint stands for unsigned integer.
The command line arguments that should be supported are:
-f str // path to SoR file to be read |
-from uint // starting position in the file (in bytes) |
-len uint // number of bytes to read |
-print_col_type uint // print the type of a column: BOOL, INT, FLOAT, STRING |
-print_col_idx uint uint // the first argument is the column, the second is the offset |
-is_missing_idx uint uint // is there a missing in the specified column offset |
Assume "data.sor" is:
<0> <23> <hi> |
<1> <12> <> |
<1> <1> |
Some interactions with your program are:
$ ./sorer -f "data.sor" -from 0 -len 100 -print_col_type 0 |
BOOL |
$ ./ sorer -f "data.sor" -from 0 -len 100 -print_col_type 2 |
STRING |
$ ./sorer -f "data.sor" -from 0 -len 100 -is_missing_idx 2 0 |
0 |
$ ./sorer -f "data.sor" -from 0 -len 100 -is_missing_idx 2 1 |
1 |
$ ./sorer -f "data.sor" -from 0 -len 100 -is_missing_idx 2 2 |
1 |
$ ./sorer -f "data.sor" -from 0 -len 100 -print_col_idx 2 0 |
"hi" |
$ ./sorer -f "data.sor" -from 5 -len 100 -print_col_idx 1 0 |
12 |
Your submission should include a directory called part1 with your code and with a README file describing your code. Your submission should have a Dockerfile (it could be the same that we gave you). You should give us a Makefile that builds and runs your program in our Docker image.
Part II: Design
In this part you are tasked to design the CwC API, via class and method signatures/stubs, of a data structure that is likely going to be widely used in your company. That is, you should define the methods’ names and their signatures, but not yet implement them. Standard libraries are not available as they use features that the company style guide has prohibited. Your team should design a basic API for an Object class, and one of the following classes: Array, Queue, or a Map.
The deliverable here is, in a separate directory called part2, a set of class declarations via a set of .h files and test cases via a .cpp file. Each pair shall pick one of {Array, Queue or Map}. You may design auxiliary or helper classes if you feel that is warranted. The test cases should confirm that an implementation of the API is correct.
The constraint you are operating under is that, on the one hand, you have to stick to the CwC language that has been adopted in your company, but on the other hand you are expecting that you will need to have data structures containing different types. Your design should avoid code duplication but also enable catching errors as early as possible.
For Array, your design should accommodate at least Arrays of Object and String. For Queue, your design should accommodate at least Queues of Object and String. For Map, you should support String to String and String to Object (at least). It should not be too hard for a user to use your design with other kinds of data.
Summary of deliverables. When you submit, there should be two directories. One, named part1, with a Makefile, a Dockerfile, a README.md and your implementation of sorer; the second, named part2, containing a README, some .h files, and a test-{array|queue|map}.cpp file. Furthermore there should be a file named REPO.md containing on the first line the HTTPS-clone URL of a public repository on GitHub.com (this should end in a .git. We will be using this to clone your repository) that contains only your A1-part2 from this assignment. REPO.md should be otherwise empty.
submission/ # your team's submissions |
part1/ |
Makefile |
build # build an executable inside docker |
test # runs your tests inside docker |
Dockerfile # your docker file with everything needed to build/run |
..code.. |
README.md # 1 page description of the code for part 1 |
part2/ # part2 implements one of map, array, queue |
README.md # 1 page description of the API you created for part 2 |
object.h # interface only / no code // definitely add comments |
array.h # interface only / no code // definitely add comments (this filename assumes you chose to implement array) |
test-array.cpp # tests (again the filename assumes you chose to implement array) |
REPO.md # a file with the HTTPS-clone URL of the repo where all of A1 part 2 is stored |
Errata: An earlier version of the assignment did not mention explicitly that the missing value can manifest itself as the absence of a field for any number of trailing fields in a row. E.g. if we have deduced the schema as [BOOL,BOOL,STRING], the following row
< 1 > |
means
< 1 > <> <> |
Furthermore, if you find a row that does not match your schema you are fee to either ignore the whole row, or to replace the values by missing.
Submission details were added.
Warmup exercise 3
Using your W2 classes, write a program that reads a file, splits it word by word, and prints words of more than four characters long along with their occurrence count sorted in decreasing order. A word is a sequence of ASCII letters, words should be converted to lower case.
Imagine a file doc.txt:
This young gentlewoman had a father--O, that "had," how sad a passage |
'tis!--whose skill young |
Your program should work as follows:
$ ./a.out -f doc.txt |
young 2 |
gentlewoman 1 |
father 1 |
passage 1 |
whose 1 |
skill 1 |
The order of words with the same number of occurrences is not specified.
Please submit:
a file named main.cpp;
any number of .h files;
a Makefile with at least one target named docker to compile in our docker image and create an executable named a.out. Information about the docker image will be on Piazza.
Hints: Consider using C library functions for opening a file and reading its content as one large character array, use library functions to test if a character is a letter, and converting letter to lower case. For sorting, your W2 class should be used.
Warmup exercise 2
Your task is to implement the following classes: Object, String, StrList, SortedStrList. Object is the parent of String and StrList. StrList is the parent of SortedStrList.
The choice of what methods to include in the Object class is part of this assignment. Similarly for the String class.
The SortedStrList class maintains its elements in increasing alphanumeric order.
The methods on StrList must include the following:
void push_back(String* e) // Appends e to end void add(size_t i, String* e) // Inserts e at i void add_all(size_t i, StrList* c) // Inserts all of elements in c into this list at i void clear() // Removes all of elements from this list bool equals(Object* o) // Compares o with this list for equality. String* get(size_t index) // Returns the element at index size_t hash() // Returns the hash code value for this list. size_t index_of(Object* o) // Returns the index of the first occurrence of o, or >size() if not there String* remove(size_t i) //Removes the element at i String* set(size_t i, String* e) // Replaces the element at i with e size_t size() // Return the number of elements in the collection
The sorted list class has one extra method called sorted_add.
You will be provided with a test file that must compile and run succesfully.
The following is an example of what such a test file may look like.
#include "helper.h" // Your file, with any C++ code that you need #include "object.h" // Your file with the CwC declaration of Object #include "string.h" // Your file with the String class #include "list.h" // Your file with the two list classes void FAIL() { exit(1); } void OK(const char* m) { /** print m */ } void t_true(bool p) { if (!p) FAIL(); } void t_false(bool p) { if (p) FAIL(); } void test1() { String * s = new String("Hello"); String * t = new String("World"); String * u = s->concat(t); t_true(s->equals(s)); t_false(s->equals(t)); t_false(s->equals(u)); OK("1"); } void test2() { String * s = new String("Hello"); String * t = new String("World"); String * u = s->concat(t); SortedStrList * l = new SortedStrList(); l->sorted_add(s); l->sorted_add(t); l->sorted_add(u); t_true(l->get(0)->equals(s)); OK("2"); } void test3() { String * s = new String("Hello"); String * t = new String("World"); String * u = s->concat(t); SortedStrList * l = new SortedStrList(); l->sorted_add(s); l->sorted_add(t); l->sorted_add(u); SortedStrList * l2 = new SortedStrList(); l2->sorted_add(s); l2->sorted_add(t); l2->sorted_add(u); t_true(l->equals(l2)); t_true(l2->equals(l)); t_true(l->hash() == l2->hash()); OK("3"); } void test4() { String * s = new String("Hello"); String * t = new String("World"); String * u = s->concat(t); SortedStrList * l = new SortedStrList(); l->sorted_add(s); l->sorted_add(t); l->sorted_add(u); SortedStrList * l2 = new SortedStrList(); l2->add_all(0,l); t_true(l->size() == l2->size()); OK("4"); } int main() { test1(); test2(); test3(); test4(); return 0; }
Errata: An earlier version of the assignment had a mistake in test2(). Also the signature of add_all, equals and index_of were lacking a *. Lastly, index_of was changed to return a size_t rather than an int. The set() method’s first argument was changed from int to size_t.
Warmup exercise 1
Your task is to write a program that consists of at least two functions:
void print(size_t ms, char* s, char * c) int main(int argc, char** argv)
Print can be written in full C++ and should print its arguments to the console. The main function is in CwC, reads command line arguments and calls print(). Your program should accept two command line flags:
-i followed by a positive integer
-f followed by a string
The program should accept an optional argument, a string, coming at the end of the argument list. If any argument is missing it should be replaced by either the empty string or the number 0. Multiple occurrences of a flag is incorrect.
If your program is named a.out, a valid invocation could be
$ a.out -f file.cpp -i 12 “this is a comment” |
this should result in a call to print with arguments 12, “file.cpp” and “this is a comment”.
For this assignment any error should result in termination of the program.
You submission should also have a Makefile with a target to compile and a target to test it.
Here is a simple example of how to create a Makefile with tests:
$ cat > Makefile |
test: |
- ./a.out -f file |
- ./a.out -i 122222 -f face comment |
- ./a.out comment |
Try to think of interesting inputs.
Submission details will be posted on Piazza before the deadline.